
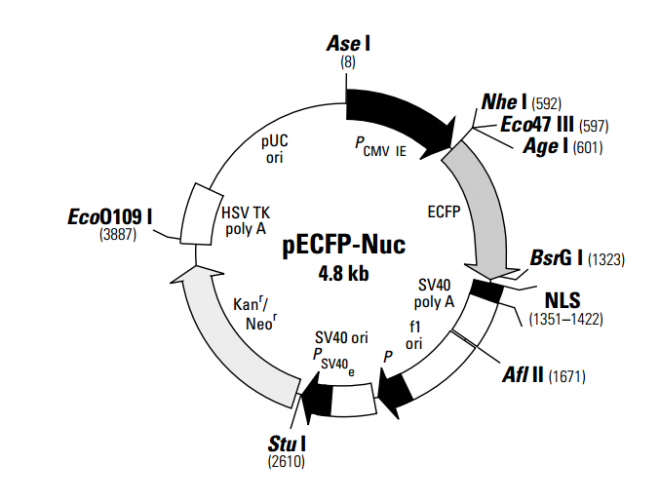
pECFP-Nuc
- 产品货号GS-1817
- 销售价格¥ 680
- 包装规格2μg质粒或0.5ml甘油菌
- 载体抗性Kanamycin (卡那霉素)
- 筛选标记Neomycin (新霉素)
- 载体大小4764 bp
- 启动子CMV
pECFP-Nuc encodes an enhanced cyan fluorescent variant of the?Aequorea victoria?green fluorescent protein (GFP) gene with three copies of the nuclear localization signal (NLS) of the simian virus 40 large T-antigen fused at its C-terminus (1, 2). The reiteration of the NLS sequence significantly increases the efficiency of translocation of ECFP into the nucleus of mammalian cells (3). The ECFP gene contains six amino acid substitutions. The Tyr-66 to Trp substitution gives ECFP fluorescence excitation (major peak at 433 nm and a minor peak at 453 nm) and emission (major peak at 475 nm and a minor peak at 501 nm) similar to other cyan emission variants (4-6). The five other substitutions enhance the brightness and solubility of the protein, primarily due to improved protein-folding properties and efficiency of chromophore formation (5, 7 & 8).
In addition to the chromophore mutations, ECFP contains >190 silent mutations that create an open reading frame comprised almost entirely of preferred human codons (9). Furthermore, upstream sequences flanking ECFP have been converted to a Kozak consensus translation initiation site (10). These changes increase the translational efficiency of the ECFP mRNA and consequently the expression of ECFP in mammalian and plant cells.
The vector contains an SV40 origin for replication and a neomycin resistance (Neor) gene for selection (using G418) in eukaryotic cells. A bacterial promoter (P) upstream of Neor?expresses kanamycin resistance in?E. coli. The vector backbone also provides a pUC19 origin of replication for propagation in?E. coli?and an f1 origin for single-stranded DNA production. The ECFP-Nuc vector can be transfected into mammalian cells using any standard transfection method. If desired, stable transfectants can be selected using G418 (11).
载体应用
pECFP-Nuc is used for the localized expression of ECFP in the nucleus of mammalian cells. It allows the visualization of the nucleus in living and fixed cells using fluorescence microscopy. ECFP can be used for dual-labeling experiments together with EYFP or EYFP fusion proteins using standard fluorescence microscopy when the appropriate filter sets are applied. Visit here for a complete listing of recommended filter sets. pECFP-Nuc is not meant to be used as a cloning vector. However, unique restriction sites at the 5' end of ECFP, between ECFP and the three copies of the NLS, and at the 3' end of the fusion protein, allow excision or insertion of DNA.
0001 TAGTTATTAA TAGTAATCAA TTACGGGGTC ATTAGTTCAT AGCCCATATA TGGAGTTCCG
0061 CGTTACATAA CTTACGGTAA ATGGCCCGCC TGGCTGACCG CCCAACGACC CCCGCCCATT
0121 GACGTCAATA ATGACGTATG TTCCCATAGT AACGCCAATA GGGACTTTCC ATTGACGTCA
0181 ATGGGTGGAG TATTTACGGT AAACTGCCCA CTTGGCAGTA CATCAAGTGT ATCATATGCC
0241 AAGTACGCCC CCTATTGACG TCAATGACGG TAAATGGCCC GCCTGGCATT ATGCCCAGTA
0301 CATGACCTTA TGGGACTTTC CTACTTGGCA GTACATCTAC GTATTAGTCA TCGCTATTAC
0361 CATGGTGATG CGGTTTTGGC AGTACATCAA TGGGCGTGGA TAGCGGTTTG ACTCACGGGG
0421 ATTTCCAAGT CTCCACCCCA TTGACGTCAA TGGGAGTTTG TTTTGGCACC AAAATCAACG
0481 GGACTTTCCA AAATGTCGTA ACAACTCCGC CCCATTGACG CAAATGGGCG GTAGGCGTGT
0541 ACGGTGGGAG GTCTATATAA GCAGAGCTGG TTTAGTGAAC CGTCAGATCC GCTAGCGCTA
0601 CCGGTCGCCA CCATGGTGAG CAAGGGCGAG GAGCTGTTCA CCGGGGTGGT GCCCATCCTG
0661 GTCGAGCTGG ACGGCGACGT AAACGGCCAC AAGTTCAGCG TGTCCGGCGA GGGCGAGGGC
0721 GATGCCACCT ACGGCAAGCT GACCCTGAAG TTCATCTGCA CCACCGGCAA GCTGCCCGTG
0781 CCCTGGCCCA CCCTCGTGAC CACCCTGACC TGGGGCGTGC AGTGCTTCAG CCGCTACCCC
0841 GACCACATGA AGCAGCACGA CTTCTTCAAG TCCGCCATGC CCGAAGGCTA CGTCCAGGAG
0901 CGCACCATCT TCTTCAAGGA CGACGGCAAC TACAAGACCC GCGCCGAGGT GAAGTTCGAG
0961 GGCGACACCC TGGTGAACCG CATCGAGCTG AAGGGCATCG ACTTCAAGGA GGACGGCAAC
1021 ATCCTGGGGC ACAAGCTGGA GTACAACTAC ATCAGCCACA ACGTCTATAT CACCGCCGAC
1081 AAGCAGAAGA ACGGCATCAA GGCCAACTTC AAGATCCGCC ACAACATCGA GGACGGCAGC
1141 GTGCAGCTCG CCGACCACTA CCAGCAGAAC ACCCCCATCG GCGACGGCCC CGTGCTGCTG
1201 CCCGACAACC ACTACCTGAG CACCCAGTCC GCCCTGAGCA AAGACCCCAA CGAGAAGCGC
1261 GATCACATGG TCCTGCTGGA GTTCGTGACC GCCGCCGGGA TCACTCTCGG CATGGACGAG
1321 CTGTACAAGT CCGGACTCAG ATCTCGAGCT GATCCAAAAA AGAAGAGAAA GGTAGATCCA
1381 AAAAAGAAGA GAAAGGTAGA TCCAAAAAAG AAGAGAAAGG TAGGATCCAC CGGATCTAGA
1441 TAACTGATCA TAATCAGCCA TACCACATTT GTAGAGGTTT TACTTGCTTT AAAAAACCTC
1501 CCACACCTCC CCCTGAACCT GAAACATAAA ATGAATGCAA TTGTTGTTGT TAACTTGTTT
1561 ATTGCAGCTT ATAATGGTTA CAAATAAAGC AATAGCATCA CAAATTTCAC AAATAAAGCA
1621 TTTTTTTCAC TGCATTCTAG TTGTGGTTTG TCCAAACTCA TCAATGTATC TTAAGGCGTA
1681 AATTGTAAGC GTTAATATTT TGTTAAAATT CGCGTTAAAT TTTTGTTAAA TCAGCTCATT
1741 TTTTAACCAA TAGGCCGAAA TCGGCAAAAT CCCTTATAAA TCAAAAGAAT AGACCGAGAT
1801 AGGGTTGAGT GTTGTTCCAG TTTGGAACAA GAGTCCACTA TTAAAGAACG TGGACTCCAA
1861 CGTCAAAGGG CGAAAAACCG TCTATCAGGG CGATGGCCCA CTACGTGAAC CATCACCCTA
1921 ATCAAGTTTT TTGGGGTCGA GGTGCCGTAA AGCACTAAAT CGGAACCCTA AAGGGAGCCC
1981 CCGATTTAGA GCTTGACGGG GAAAGCCGGC GAACGTGGCG AGAAAGGAAG GGAAGAAAGC
2041 GAAAGGAGCG GGCGCTAGGG CGCTGGCAAG TGTAGCGGTC ACGCTGCGCG TAACCACCAC
2101 ACCCGCCGCG CTTAATGCGC CGCTACAGGG CGCGTCAGGT GGCACTTTTC GGGGAAATGT
2161 GCGCGGAACC CCTATTTGTT TATTTTTCTA AATACATTCA AATATGTATC CGCTCATGAG
2221 ACAATAACCC TGATAAATGC TTCAATAATA TTGAAAAAGG AAGAGTCCTG AGGCGGAAAG
2281 AACCAGCTGT GGAATGTGTG TCAGTTAGGG TGTGGAAAGT CCCCAGGCTC CCCAGCAGGC
2341 AGAAGTATGC AAAGCATGCA TCTCAATTAG TCAGCAACCA GGTGTGGAAA GTCCCCAGGC
2401 TCCCCAGCAG GCAGAAGTAT GCAAAGCATG CATCTCAATT AGTCAGCAAC CATAGTCCCG
2461 CCCCTAACTC CGCCCATCCC GCCCCTAACT CCGCCCAGTT CCGCCCATTC TCCGCCCCAT
2521 GGCTGACTAA TTTTTTTTAT TTATGCAGAG GCCGAGGCCG CCTCGGCCTC TGAGCTATTC
2581 CAGAAGTAGT GAGGAGGCTT TTTTGGAGGC CTAGGCTTTT GCAAAGATCG ATCAAGAGAC
2641 AGGATGAGGA TCGTTTCGCA TGATTGAACA AGATGGATTG CACGCAGGTT CTCCGGCCGC
2701 TTGGGTGGAG AGGCTATTCG GCTATGACTG GGCACAACAG ACAATCGGCT GCTCTGATGC
2761 CGCCGTGTTC CGGCTGTCAG CGCAGGGGCG CCCGGTTCTT TTTGTCAAGA CCGACCTGTC
2821 CGGTGCCCTG AATGAACTGC AAGACGAGGC AGCGCGGCTA TCGTGGCTGG CCACGACGGG
2881 CGTTCCTTGC GCAGCTGTGC TCGACGTTGT CACTGAAGCG GGAAGGGACT GGCTGCTATT
2941 GGGCGAAGTG CCGGGGCAGG ATCTCCTGTC ATCTCACCTT GCTCCTGCCG AGAAAGTATC
3001 CATCATGGCT GATGCAATGC GGCGGCTGCA TACGCTTGAT CCGGCTACCT GCCCATTCGA
3061 CCACCAAGCG AAACATCGCA TCGAGCGAGC ACGTACTCGG ATGGAAGCCG GTCTTGTCGA
3121 TCAGGATGAT CTGGACGAAG AGCATCAGGG GCTCGCGCCA GCCGAACTGT TCGCCAGGCT
3181 CAAGGCGAGC ATGCCCGACG GCGAGGATCT CGTCGTGACC CATGGCGATG CCTGCTTGCC
3241 GAATATCATG GTGGAAAATG GCCGCTTTTC TGGATTCATC GACTGTGGCC GGCTGGGTGT
3301 GGCGGACCGC TATCAGGACA TAGCGTTGGC TACCCGTGAT ATTGCTGAAG AGCTTGGCGG
3361 CGAATGGGCT GACCGCTTCC TCGTGCTTTA CGGTATCGCC GCTCCCGATT CGCAGCGCAT
3421 CGCCTTCTAT CGCCTTCTTG ACGAGTTCTT CTGAGCGGGA CTCTGGGGTT CGAAATGACC
3481 GACCAAGCGA CGCCCAACCT GCCATCACGA GATTTCGATT CCACCGCCGC CTTCTATGAA
3541 AGGTTGGGCT TCGGAATCGT TTTCCGGGAC GCCGGCTGGA TGATCCTCCA GCGCGGGGAT
3601 CTCATGCTGG AGTTCTTCGC CCACCCTAGG GGGAGGCTAA CTGAAACACG GAAGGAGACA
3661 ATACCGGAAG GAACCCGCGC TATGACGGCA ATAAAAAGAC AGAATAAAAC GCACGGTGTT
3721 GGGTCGTTTG TTCATAAACG CGGGGTTCGG TCCCAGGGCT GGCACTCTGT CGATACCCCA
3781 CCGAGACCCC ATTGGGGCCA ATACGCCCGC GTTTCTTCCT TTTCCCCACC CCACCCCCCA
3841 AGTTCGGGTG AAGGCCCAGG GCTCGCAGCC AACGTCGGGG CGGCAGGCCC TGCCATAGCC
3901 TCAGGTTACT CATATATACT TTAGATTGAT TTAAAACTTC ATTTTTAATT TAAAAGGATC
3961 TAGGTGAAGA TCCTTTTTGA TAATCTCATG ACCAAAATCC CTTAACGTGA GTTTTCGTTC
4021 CACTGAGCGT CAGACCCCGT AGAAAAGATC AAAGGATCTT CTTGAGATCC TTTTTTTCTG
4081 CGCGTAATCT GCTGCTTGCA AACAAAAAAA CCACCGCTAC CAGCGGTGGT TTGTTTGCCG
4141 GATCAAGAGC TACCAACTCT TTTTCCGAAG GTAACTGGCT TCAGCAGAGC GCAGATACCA
4201 AATACTGTCC TTCTAGTGTA GCCGTAGTTA GGCCACCACT TCAAGAACTC TGTAGCACCG
4261 CCTACATACC TCGCTCTGCT AATCCTGTTA CCAGTGGCTG CTGCCAGTGG CGATAAGTCG
4321 TGTCTTACCG GGTTGGACTC AAGACGATAG TTACCGGATA AGGCGCAGCG GTCGGGCTGA
4381 ACGGGGGGTT CGTGCACACA GCCCAGCTTG GAGCGAACGA CCTACACCGA ACTGAGATAC
4441 CTACAGCGTG AGCTATGAGA AAGCGCCACG CTTCCCGAAG GGAGAAAGGC GGACAGGTAT
4501 CCGGTAAGCG GCAGGGTCGG AACAGGAGAG CGCACGAGGG AGCTTCCAGG GGGAAACGCC
4561 TGGTATCTTT ATAGTCCTGT CGGGTTTCGC CACCTCTGAC TTGAGCGTCG ATTTTTGTGA
4621 TGCTCGTCAG GGGGGCGGAG CCTATGGAAA AACGCCAGCA ACGCGGCCTT TTTACGGTTC
4681 CTGGCCTTTT GCTGGCCTTT TGCTCACATG TTCTTTCCTG CGTTATCCCC TGATTCTGTG
4741 GATAACCGTA TTACCGCCAT GCAT